Distributed System 分布式系统设计概述
1.需求明确(Requirements clarifications)
因为系统设计往往是开放性的,而且答案不止一个,所以非常需要在一开始就弄清楚需求
以设计 Twitter 系统举例,一开始就要问清楚:
- 有多少用户, 会使用发推特和关注其他人服务?
- 是否也需要设计时间线(Timeline)的功能?
- 是否推特需要包括图片和视频?
- 是否只需要关注后端, 还是前端也需要开发?
- 是否用户可以搜索推特?
- 是否需要展示热搜主题?
- 是否需要发送推送新推特通知?
2.系统接口定义(System interface definition)
定义有哪些 API,不仅可以建立系统,而且可以确保不会偏离需求
以设计 Twitter 系统举例:
- postTweet(user_id, tweet_data, tweet_location, user_location, timestamp, …)
- generateTimeline(user_id, current_time, user_location, …)
- markTweetFavorite(user_id, tweet_id, timestamp, …)
3.初略的估算(Back-of-the-envelope estimation)
大致的估算系统的规模,可以帮助后面的详细设计
以设计 Twitter 系统举例:
- 系统大概规模多大?
- 新推特的数量,单条推特的访问量,每秒钟生成时间线的数量
- 多大的存储需要?
- 如果需要保存图片和视频,那么存储大小明显不同于纯文字
- 网络的带宽需要多大?
- 带宽决定了我们要怎么管理流量和负载均衡
4.定义数据模型(Defining data model)
定义数据模型可以表明数据将在系统的不同组件中怎么流通,并且指引数据的切分和管理(存储、传输、加密等)
使用什么数据库? NoSQL 还是 MySQL?
使用什么存储图片和视频?
以设计 Twitter 系统举例:
- User: UserID, Name, Email, DoB, CreationData, LastLogin, etc.
- Tweet: TweetID, Content, TweetLocation, NumberOfLikes, TimeStamp, etc.
- UserFollowo: UserdID1, UserID2
- FavoriteTweets: UserID, TweetID, TimeStamp
5.概要设计(High-level design)
画一个框图,包含系统的大致组件(5到6个可能)
以设计 Twitter 系统举例:
- 需要不同的应用服务器来处理读/写请求,并且需要用到负载均衡来处理流量分发
- 如果读的流量很大(相比于写的),那么需要独立的服务器来处理这个场景
- 需要一个高效的数据库来存储数据
- 需要一个分布式文件系统来存储图片和视频
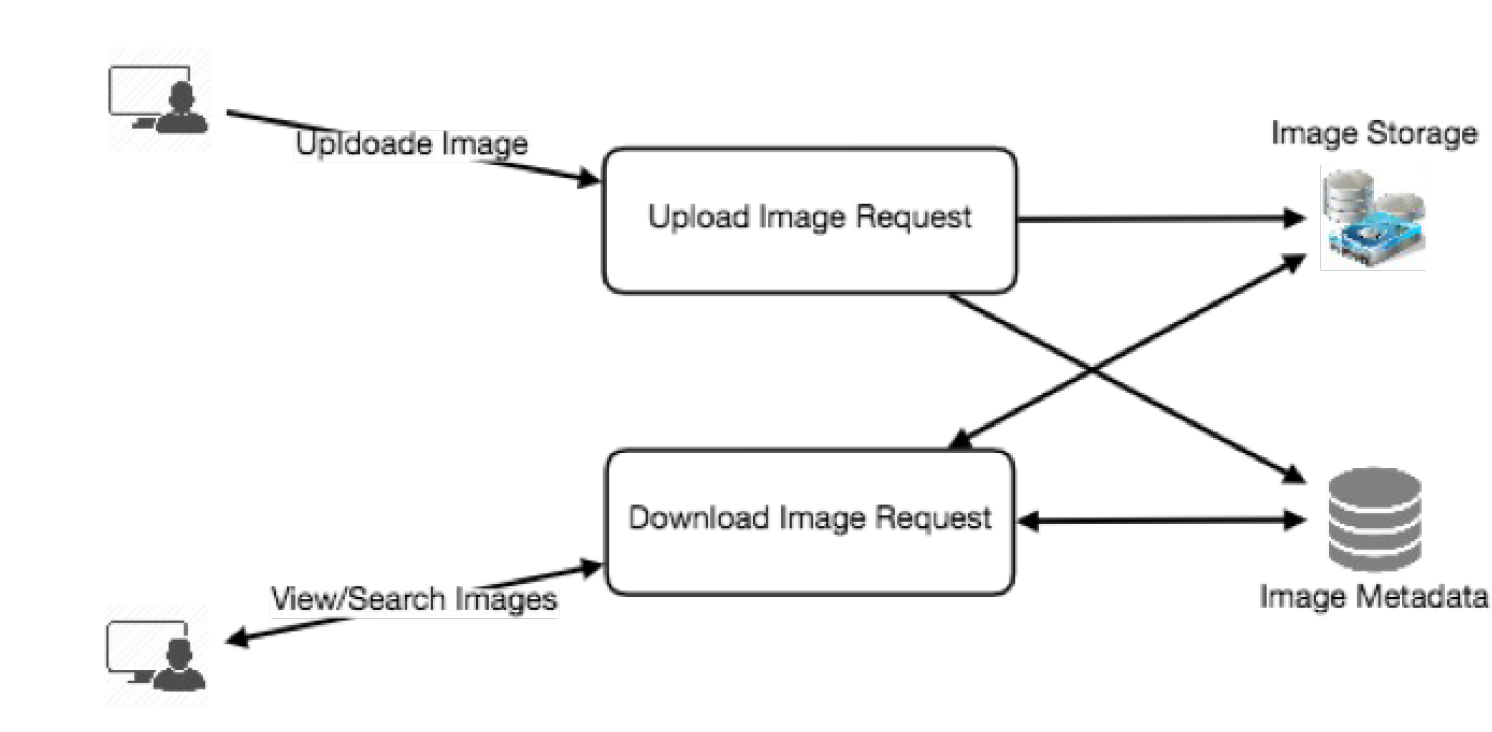
6.详细设计(Detailed design)
深入 2 到 3个组件进行设计
我们需要展示出不同的设计方法,以及他们之间的优缺点,怎么做取舍
以设计 Twitter 系统举例:
- 因为我们要处理海量的数据,那么我们需要怎么样切分数据分布到不同的数据库?
- 我们是否存储所有的用户数据到单数据库?
- 有可能出现哪些问题?
- 我们是否存储所有的用户数据到单数据库?
- 我们要怎么处理发推很多/关注很多人的狂热用户?
- 因为用户的时间线会包含最新最相关的推特,是否我们需要通过优化数据的存储方式来方便最快查找?
- 在哪一层需要引入缓存来加速,需要多大的缓存?
- 哪些组件需要更好的负载均衡?
7.指出和处理瓶颈(Identifying and resolving bottlenecks)
尽可能多的指出瓶颈,以及减轻它们的方式
以设计 Twitter 系统举例:
- 系统中是否有任意的单点失败的情况?
- 当一些服务器出问题时,是否有足够的数据备份?
- 是否有足够的服务备份,来避免系统整个挂掉?
- 怎么跟踪服务的性能?当一些重要的组件失效时是否能收到警报?