本文介绍朴素贝叶斯算法(Naive Bayesian)。
决策树算法类似于用流程图进行分类判断。
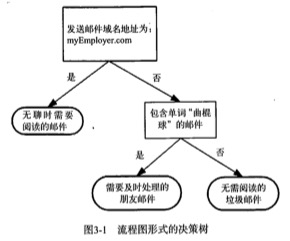
构造
- 优点:在数据较少的情况下仍然有效,可以处理多类别问题;
- 缺点:对于输入数据的准备方式较为敏感;
- 使用数据类型:标称型。
流程
- 收集数据:可以使用任何方法;
- 准备数据:需要数值型或者布尔型数据;
- 分析数据:有大量特征时,绘制特征作用不大,此时使用直方图效果更好;
- 训练算法:计算不同的独立特征的条件概率;
- 测试算法:计算错误率;
- 使用算法:一个常见的朴素贝叶斯应用是分档分类。可以在任意的分类场景中使用朴素贝叶斯分类器,不一定非要是文本。
理论
贝叶斯决策
假设有一个数据集,由两类数据组成:
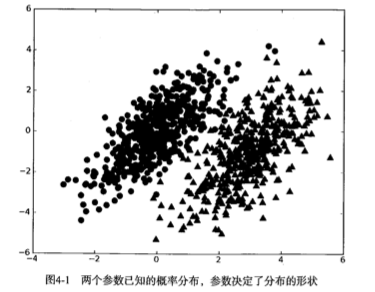
假设任意数据点(x, y)属于类别1的概率为p1(x, y),属于类别2的概率为p2(x, y),那么判断类别的方式可以为:
- 如果p1(x, y) > p2(x, y),那么类别为1;
- 如果p2(x, y) > p1(x, y),那么类别为2。
贝叶斯决策理论的核心思想:选择高概率对应的类别。
条件概率
有两桶石头A和B,由灰色和黑色组成:
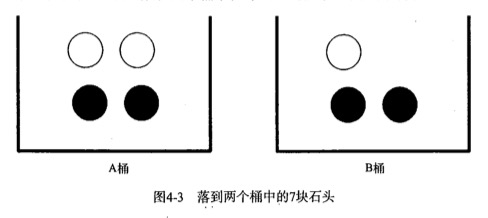
从B中,取出灰色石头的概率为:
$$P(gray|bucketB) = P(gray\ and\ bucketB) / P(bucketB)$$
其中,$P(gray\ and\ bucketB)$是1/7(B中灰色石头的个数除以两个桶石头的总数), $P(bucketB)$是用3/7,则计算结果为1/3。
贝叶斯准则:如果已知P(x|c),要求P(c|x),则可用公式:
$$P(c|x) = \frac{P(x|c)P(c)}{P(x)}$$