本文讲解了如何从零开始,一步步做一个拼音输入法。
思路是这样的,首先,需要一个词库,这个词库包含单字的和词组的,其次,需要进行一场串字母的切割算法(bdu切分为b、du),最后需要一个检索和排序算法,来应对类似首字母检索(sz对应深圳)和部分字母检索(shenz对应深圳)等各种情况。下面介绍我是怎么从零开始做一款拼音输入法的。
词库
单字
单字的词库,由于有汉字词典,所以比较简单,这里用的是网上一个开源的词库文件:
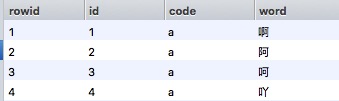
数目为3万多,但是里面包含了许多基本不会用到的偏僻字:

具体的排除偏僻字的方法后面会介绍。
词组
词组的词库,由于做输入法的出发点,是为了搜索地图里面的POI点服务的,所以优先考虑地理词,一开始想到的是用搜狗细胞词库上面的所有城市的精选地理信息:

解析方法参考:Java-解析搜狗输入法分类词库scel文件
但是这样的方式,后来在使用中,发现其虽然包含了非常多的地理信息,但是对于输入法来说,并不好用,原因在于,用户其实是更习惯于用常用字来检索的,例如:用户输入“baidu”,是想要打出“百度”这样的常用字,而不是像“柏渡”这样类似的地理词。
基于此,后面的词组词库是用的搜狗以前版本的核心词库,解析方法参考:
Java-解析搜狗输入法核心词库sgim_core.bin文件。
有点麻烦的是,搜狗的词库只有汉字,并没有对应的拼音,所以这里用pinyin4j来做转换,转换方法参考:Java-汉字转拼音。
数目为42万多,但是里面同样也包含了很多的偏僻词组,排除方法后面会介绍。
排序
由于是输入法,排序规则显然是越常用的排越前面,但是由于用到的词库并没有词频,所以必须想办法通过机器去自动生成词频,以便进行常用性排序。
对于这一点,在经过思考以后,决定采用百度搜索引擎来进行数据搜集。在百度搜索引擎搜索每个词组时,可以看到有多少个相关的结果,我们有理由相信,越多的相关结果,意味着被检索的次数也多,也就越常用。
下面是对于”kebi”对应的“科比”和“可鄙”在百度搜索引擎的结果数对比:


可以看到,”科比”的搜索相关结果更多,显然也更常用。
基于这一策略,通过对词库中的单字和词组进行百度指数(结果数/万)的爬虫搜集,这里涉及到跟百度反爬虫部门的斗智斗勇,包括不定时切IP等,不过最终还是成功把45万词条的数据爬取下来了,部分结果如下:
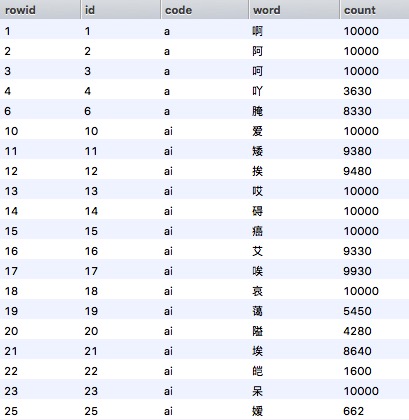
完成以后,根据百度指数,设置一个阈值(这里是100),小于100的就判断为生僻字和词组,将其从词库中删除,最终只保留了33万条词条。
场景
地理词
由于我们的输入法的使用场景主要在于地图的搜索POI点,所以,我们如果能判断一个词组是否是地理词,将其排在更前面,则体验上会更好。基于我们在排序中的思路,考虑从百度检索结果中看能不能进一步挖掘价值。
下面是搜索两个地理词,“深圳”和”南山”在百度搜索引擎的结果:
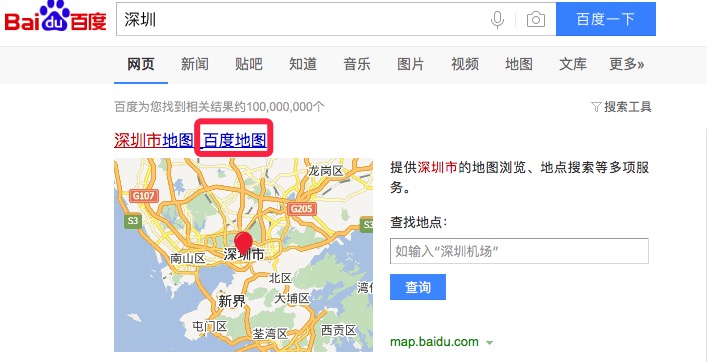
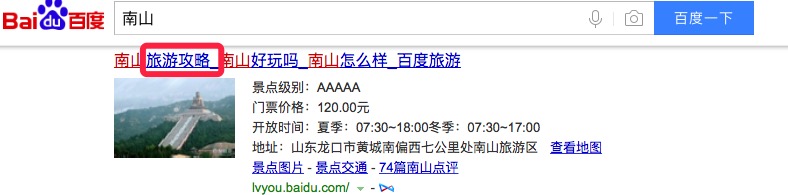
可以看出,地理词在检索结果中,很可能会出现“地图”和“旅游攻略”字眼,我们可以以此为依据,来判断一个词为地理词。依旧通过爬虫,新一轮的斗智斗勇后,成功地识别出来了地理词。
下面是识别出来的首字母为”ns“的地理词列表:
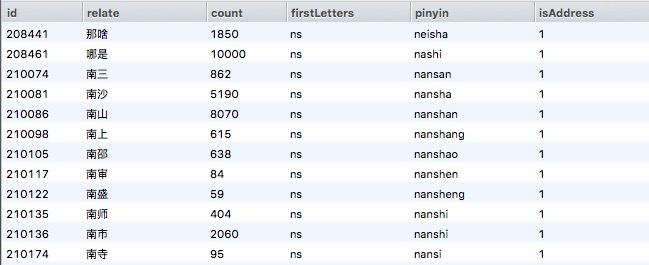
从结果来看,显然这策略也并不是完美的,会出现一些词的误判,例如“那啥”,但是从最终效果来看,还是非常好的。
选择词
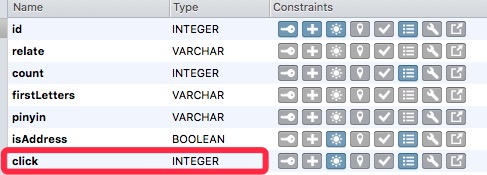
对于用户已经选择过的词,我们应该在用户再次输入的时候出现在最前面。因此,我们在词库中加入一个“click”字段,用于记录该词的被选择次数,次数越多的,更高优先级展示给用户。
切割
通过上述步骤解决了,词库的建立,词组的常用性排序,地理词的识别以及记录用户选择次数后,我们就搭建起了一个完整可用的词库。
在此基础上,我们需要在用户输入一串字母的时候,对其进行切割,例如,baidu切割成bai和du,szhen切割成s和zhen。对于这一点,这里用到的是一个基于拼音语法规则的正则表达式:
1 | [^aoeiuv]?h?[iuv]?(ai|ei|ao|ou|er|ang?|eng?|ong|a|o|e|i|u|ng|n)? |
这个正则表达式可以正确地分割出长串的字母为单个的拼音,例如分割:
1 | tebieshuai |
但是,在测试中,发现其分割有缺陷,例如,对于分割”hn”,直接分割成了“hn”,而正确的分割是”h n”,所以,针对这种情况,做了容错处理,后面会介绍。
检索
切割完成后,我们需要将其从词库中检索出来对应的词语。
以“szhen”举例,切割完成后,是”s”和“zhen”,首先,我们可以确认其首字母为”sz”,其次,我们可以确定,全拼音的匹配正则表达式为:
1 | s%zhen% |
其中,“%”表示零个或多个字母。
利用Sqlite的LIKE来进行全拼音正则匹配,并对地理词和用户选择词进行优先排序,最后根据百度指数进行排序,查询语句为:
1 | select distinct relate from relate where firstLetters ='sz' and pinyin like 's%zhen%' order by click desc, isAddress desc, count desc, length(pinyin) limit 100; |
这里,由于交互上的需求,用户选择过的词排在最前面,后面固定出现三个地理词,再后面的词,根据百度指数进行排序。对于上文提到的“hn”分割错误导致的异常,这里需要将其当成是纯首字母检索处理。
效果
为了查看最终的交互效果,我们随机取几个字符串,来看看匹配结果与搜狗输入法进行对比:
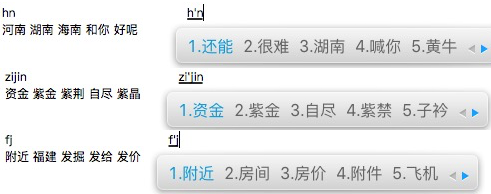
可以看到,在常用词上,两者出现的词基本重合,而本文的输入法,在地理词上,体验要更好。
最后放上加上界面开发的成果图: